LSTM+Transformer モデルによるテキスト生成(日本語の歌詞生成編)
Abstract
- 計算コストを抑えつつ Transformer の予測性能を活かすための LSTM+Transformer モデルを用いて日本語のテキスト生成を行った
はじめに
前回の記事「LSTM+Transformer モデルによるテキスト生成(基本編)」にて、LSTM と Transformer のハイブリッドモデル LSTM+Transformer を提案し、その性能を評価しました。 前回は英語のコーパス (Wikitext-103) を用いて文章生成の実験を行いましたが、やはり非ネイティブな言語よりネイティブな言語の方がわかりやすいので、今回は日本語のコーパスを対象に実験を行いました。
モデルについてのおさらい
詳細は前回の記事をご参照ください。
Transformer は現在の NLP において優秀なモデルではありますが、テキスト生成タスクにおいては計算コストの観点で Positional encoding(位置エンコーディング)の部分が足を引っ張ります。前回、その点を解決するために Positional encoding を LSTM に置き換えた LSTM+Transformer を提案しました。Transformer と LSTM+Transformer のモデル構成の比較は図1の通りです。
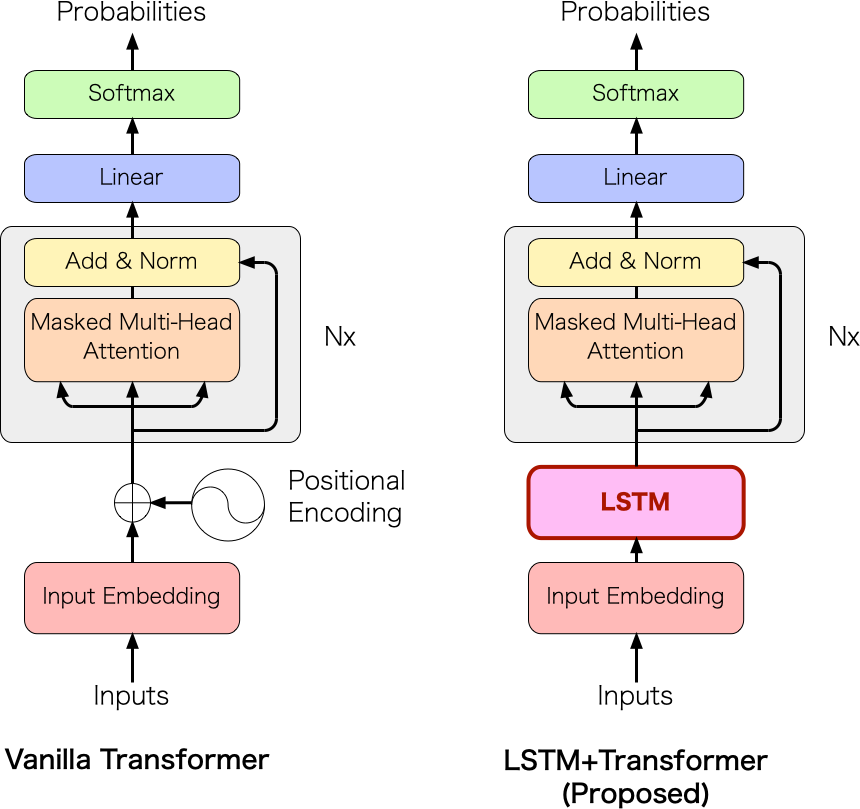
図1: Transformer と提案モデル LSTM+Transformer の構成
前回の実験の結果として、次のことがわかりました。
- LSTM+Transformer を用いることで、テキスト生成にかかる時間が Transformerから (GPU) 14% / (CPU) 69% 削減
- LSTM+Transformer の Perplexity は LSTM よりも良く、Transformer に少し劣る程度
日本語コーパスによる評価実験
ここから本題です。 今回は独自に収集した J-POP の歌詞17,901曲分を学習させました。 データの内訳は、Training: 17,701 / Validation: 100 / Test: 100 としました。 今回もモデルは [LSTM+Transformer], [Transformer], [LSTM] の3種類で検証しました。
文のトークン化
今回はオリジナルのデータセットを使用するので、何かしらの方法でトークン化する必要があります。 本実験では Sudachi (SudachiPy) (分割モードB) で事前分割した後、SentencePiece(語彙サイズ 8k)でサブワード化するという2段構成にしました。 この仕様は筆者の都合によるものなので、基本的には SentencePiece だけでも大丈夫だと思います。
2段階のトークン化を行う理由
筆者が開発している作詞支援ツールにて、歌詞の一部の単語を別の単語に置き換える機能があり、その機能を利用するにあたって人間が自然と感じる分割の単位が欲しかったためです。 ユーザには Sudachi の分割単位で表示しつつ、システム内部ではさらに SentencePiece を適用した単位で処理を行うということを想定しました。学習の設定
各モデルのパラメータを示します。前回の実験と同様です。
[LSTM+Transformer]
1層の LSTM と5層の Transformer layer で構成しました。LSTM の隠れ層および Transformer のサイズは512次元、Transformer のフィードフォワード層は1024次元としました。アテンションヘッドの数は8としました。
[Transformer]
6層の Transformer layer で構成しました。[LSTM+Transformer] での LSTM 1層分を Transformer layer に割り当てたこと以外は同上です。
[LSTM]
3層の LSTM で構成しました。隠れ層のサイズは512次元としました。
また、3つのモデルの共通設定として、エポック数は15、バッチサイズは16、一度に入力する系列長は64としました(エポック数のみ前回と異なります)。
バッチの処理
歌詞の長さ(系列長)は当然曲によってバラバラなので、バッチ内で長さを揃えるためにパディング処理を行いました。
ただし、系列長が大きく異なる曲同士が同じバッチにくると、バッチ内が <PAD> で埋め尽くされるので計算効率がかなり悪くなります。
そこで、ある程度ランダム性を保ちつつも長さの近い曲同士が同じバッチに集まるようにしました。
(AllenNLP や torchtext では BucketIterator、PyTorchNLP では BucketBatchSampler とよばれている方法を参考にしました)
系列の処理と重みの更新方法
GPU メモリのサイズの制約上、歌詞全体を一括で処理し重みを更新することはできません。今回は、基本的に系列長32ごとに重みの更新を行いました。ただし、モデルに応じて一部の処理が異なります。
- [LSTM+Transformer]: 次の系列に移る際に計算グラフを切る。1曲を通して隠れ状態および Attention 用のメモリは引き継ぐ。
- [Transformer]: 次の系列に移る際に計算グラフを切る(その他、モデル特有の処理は無し)。
- [LSTM]: 次の系列に移る際に計算グラフを切る。1曲を通して隠れ状態は引き継ぐ。
学習の結果
(詳細は後日掲載します) おおむね前回の記事と同様の傾向が見られました。提案モデル [LSTM+Transformer] の学習もうまくいっており、問題はなさそうでした。
生成文の確認
3つのモデルが実際に生成した歌詞を確認しました。ここでは抜粋したものを掲載しているので、ほかのサンプルも見たい方は こちらのページ をご参照ください。
========== [LSTM+Transformer] ==========
カワイイシャツ着て流してた催眠
真爛漫 民衆達も羨ましくシンデレラ
そんな理想のフレーズを探し駆け抜けて
杖を合わせてズブ濡れの嘘がある
チャンスを抜き 君が家族でいようね
どこまでもそうだ どこまでも駆け抜けて
.zであのコはまたもう狂った
たくさんな魂がいなくなったとき 誰もがみんなして
「またよね」と抱いたサインさ
次の展開じゃないのが決まったら また逢いに来た
[gem素) 瓦礫のステージは 全身全霊を手に入れる
大切な人への想いがbest time only ragga
no no no oh oh oh oh
そんなつもりでも背中向ける 怖がってくんないくせに
大切な人への想いが 大切な人へと 逢いに来た
[gemu] serious only 1, 2, 1, 2,1, 1, 2 1, 2, 1, 2, 1, 1, 2, 1, 1, キャッカー
たった一人の サヨナラよりも ずっと
同じ時代を思えばみんなまだ正解
片方が扉を開けても 答えは不安定だぜ
泣かないでよ そんな時代を
今の僕達
地下鉄に立ち向かって また逢いに行く
何もないみたいだ まだ間に合うから
降りそそぐ風が もう守る on stage
ライトがある 孤独に怯えながら明日に 物語が始まる
明日が見えなくなった時 誇れるものがある
それがある 容赦なく立ち
時は素直に 目をやるさ right now
ちゃんと人生でダなんて 半端ささ
それは3月13ぶつ でもアナタのおかげ
絶望のイメージちょっとさり気なく確宙にゃ歩き出す
そんな裸の足跡が どこまで行ける?
are you ready?, ここにいる
========== [Transformer] ==========
したし!さん!ないさんまょい! へんんだしわりーい!
========== [LSTM] ==========
枕を閉じたワッモノ ドライバー背負いで
月一日 ウラハラ越しで叫ぶさ
精一回怖くても 真っ直ぐに行こう
やこになった「俺のもん!」と集まってんだ
もしも男があらわれ それがすべて当てても
涙かなえんじゃない 百も承知は磨かれ
職量に負けそうになるためこう 君次第寂しいから
スタートレロンケーキ 行ききれない程を打ち取んな
グラウンドは 華麗に ほうったら 行かんじゃなきゃ
誰かが 行くだけじゃない
それでも いつまでも 聞ける
努力を恐れられてみよう 熱い情熱
今回、日本語で試してみてより明らかになりましたが、やはりどのモデルも内容に一貫性がなくデタラメな文章になっています。[LSTM+Transformer] や [LSTM] は比較的うまくいっているものを選んでこのクオリティなので、今の状態では実実用性に大きく欠けます。また、[Transformer] については完全に崩壊していて、Loss は下がる割に文法がデタラメな文章や極端に短い文章ばかり生成されます(なぜでしょう)。
おわりに
日本語の文章を対象にテキスト生成の実験を行いました。上で述べたようにまだまだ改善点が多くあります。Open AI の GPT-3 のように、潤沢な計算資源やコーパスがあれば良くなることは間違いないですが、個人の開発者でもできる範囲でなんとか工夫して良くしていきたいものです。
余談
LSTM+Transformer モデルに関しては、この実験が終わった後も改良を続けています。筆者開発の 作詞支援ツール では、2020年10月現在、学習データ約10万件の歌詞を使った LSTM+Transformer ベースのモデルを構築しており、本記事の生成文と比較して流暢性が若干改善されています。
投稿日: 2020年10月15日